Diffusion Models
May 4, 2026
Estimated Reading Time: 18 mins
Before diffusion models, image generation was largely dominated by GANs. This was despite their inherently poor training stability caused by their two competing networks. Diffusion models emerged as a more stable alternative that produce highly realistic images, and now, are the most popular model for image generation tasks. But what are diffusion models, and how do they work?
What are diffusion models?
Diffusion models are a type of generative model that learn how to transform noise into real images. They are trained by adding various amounts of random noise to images, and learning how to undo the added noise. After training, a diffusion model can transform a pure noise input into a realistic image.
Diffusion models (DDPMS) were introduced by Sohl-Dickstein et al. (2015) and popularized through Ho et al’s “Denoising Diffusion Probabilistic Models”. DDPMs have two key functionalities: the forward process, and the reverse process.
Forward Process
The forward (diffusion) process gradually adds Gaussian noise to an input image over a total of timesteps. At each timestep, the amount of noise for the current image is computed with:
represents the amount of signal, or non-noise, in the image. Conversely, the intensity of the noise at the current timestep is controlled by a noise scheduler. Ho et al. utilized a linear noise scheduler, which creates equally incremented values of from 1e-4 to 0.02. Larger timesteps produce larger values, which increasingly corrupt the input image. However, a linear scheduler produces high values for many timesteps, producing a larger portion of degraded images that are less useful to train with. Nichol & Dhariwal later proposed a cosine noise scheduler that increments more gradually to provide more informative data samples, consequently improving image generations.

Rather than computing each noisy step sequentially, the forward process can be reparameterized so we can jump directly to any timestep. We can represent as , , which means we can represent as , and , so , where represents the amount of signal . Plugging into , we get
where is sampled from Gaussian noise. The model then attempts to predict the added noise at the current timestep. To learn how to predict the added noise , the model is trained with the loss term:
which is essentially MSE loss between the true noise and the predicted noise. Interestingly, this loss term is actually a simplified version of the original term:
The original objective penalizes the model heavily for incorrect predictions on later timesteps (noisier images) so it can prioritize learning from difficult-to-denoise images. However, Ho et al. determined that the simplified loss term produces better quality samples.
Reverse Process
The reverse process undoes the forward process through a Markov chain, meaning that an image's next slightly-less noised state depends on the current noise. For each timestep, reverse diffusion slightly undoes the noise of the image until a clean image is produced. After the network predicts from image , we can compute the mean of the distribution of with
We can then find with
where if , else . When , that is the very last step of the reverse process, which is where the noiseless image is produced.
Model Architectures
To perform the noise prediction, Ho et al. (2021) utilized a modified U-Net model (Ronneberger et al., 2015). U-Net consists of a decoder, bottleneck, and encoder, with skip connections between layers of the same resolution in the encoder and decoder.
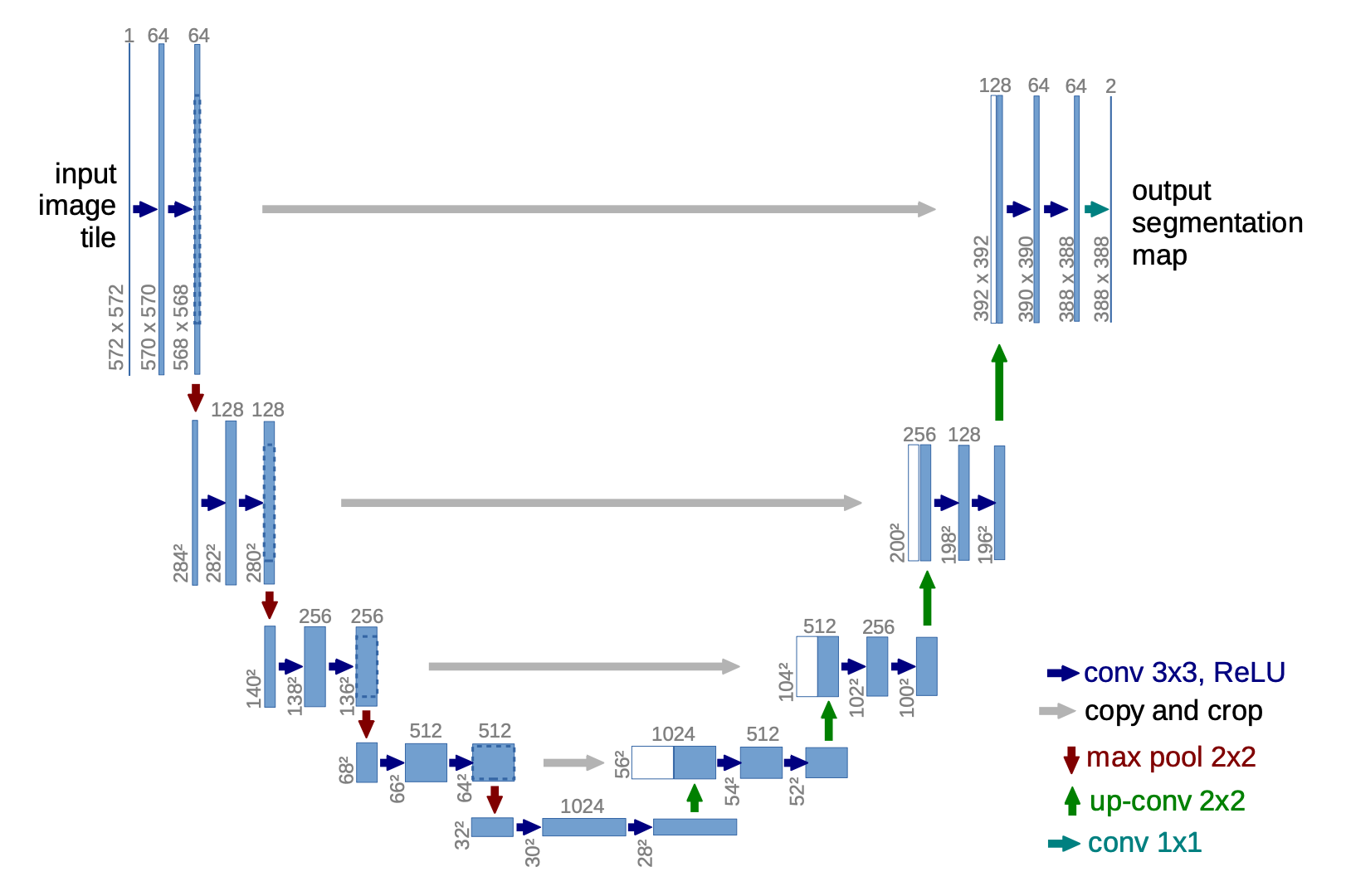
The U-Net is time-conditioned using the current timestep so the model can understand that larger timesteps correspond with noisier images. However, the timestep is not directly passed through the model because a single large integer timestep value is not informative or efficient for the model to process. Timesteps are embedded using Transformer sinusoidal positional embeddings (Vaswani et al., 2017), which turn the single integer into a vector of size that is computed with:
Cosine and sine are utilized for computing positional embeddings because they allow timestep to be a linear transformation of timestep , which allows the model to learn the relative positions between timesteps with ease. Neither cosine and sine can individually be used because when we represent the embedding as a point in a 2D unit circle, shifting timesteps requires both cosine and sine shifts. Additionally, a huge benefit of representing the timestep with sinusoidal positional embeddings is they are deterministic. No training is required to produce them.
The U-Net's blocks consist of two residual layers (He et al., 2015), with two residual blocks per image resolution. The U-Net also includes self-attention blocks (Vaswani et al., 2017) at the bottleneck and 16x16 resolution layers. These self-attention blocks pass feature maps through three linear projections (, , and ) to produce queries (), keys (), and values (). Attention weights are then computed as:
While it is unclear exactly what relationship the self-attention blocks create between pixels of a feature map, they improve denoising capabilities because they help the model create relationships between any region of a feature map. Convolutional blocks alone are insufficient for diffusion because they only learn local relationships due to their small kernel sizes.
An alternative to the U-Net in diffusion models emerged with Diffusion Transformers (DiTs) (Peebles & Xie, 2022), where a vision transformer (ViT) replaces the U-Net. The flow of a DiT is: compress an input image with a VAE encoder into a latent representation , noise , and patch with the ViT before performing forward diffusion. The benefit of using a transformer instead of an attention-based UNet is because transformers are more scalable. Larger transformers empirically perform better at diffusion generation than similarly sized UNets (Peebles & Xie, 2022).
Guided diffusion
As is, diffusion models produce diverse, uncontrollable outputs. Their generations are inherently probabilistic because their inference step begins with random noise. Diffusion models can have their outputs be guided towards a specific class or result through several methods. Basic conditioning simply involves concatenating or cross-attending (a condition image or text label) with the input before it is passed through the diffusion model. In the case of text label conditioning, the text and image must both be converted to embeddings through CLIP encoders before passing through the diffusion model.
Dhariwal & Nichol (2021) introduced classifier guided diffusion, where they train a classifier model on noisy images from forward diffusion, and use their gradients to guide the noise prediction towards the target conditioning class .
Ho & Salimans (2022) introduced classifier-free diffusion guidance, where instead of training a separate classifier, a diffusion model that is simultaneously conditioned and unconditioned is trained. During training, the condition can be randomly dropped. During inference, both conditioned and unconditioned predictions are obtained for an input sample, and the final sample is guided using:
Where is a weight that when increased, guides the generation towards the conditioned prediction while decreasing sample diversity.
Training
The flow of training a diffusion model is as follows for an input training sample :
- Randomly select a timestep value between 0 and . is a common choice.
- Add noise to input with equation (2)
- Pass the noised image, and condition if using a conditional diffusion model, into the model. Return the predicted noise .
- Pass the predicted noise and the actual noise to the loss function.
- Perform backprop.

Inference: DDPM vs. DDIM
After the diffusion model has been trained, we can input an image consisting of total noise (alongside potential conditioning) to the model, perform reverse diffusion, and produce realistic data samples. DDPM inference, however, is extremely time-consuming and compute-intensive: for all timestep values, we have to predict a denoised image. For 1000 timesteps, that means 1000 consecutive denoising operations.

Song et al. introduced denoising diffusion implicit models (DDIMs), which reparameterize the Markovian forward and reverse process to become non-Markovian. The reverse process is represented as:
At each inference step, we can directly predict the clean image with our current image and the predicted . Since we can jump directly to the cleaner image without requiring consecutive renoising steps, inference can be accelerated by taking large timestep jumps with little loss in generation quality. DDIM can reduce the 1000 timesteps of DDPM inference to ~50 steps. Because DDPMs also predict , we can use DDIM inference on DDPM-trained models.
References
-
Sohl-Dickstein et al. (2015). Deep unsupervised learning using nonequilibrium thermodynamics. arXiv
-
Ho et al. (2020). Denoising diffusion probabilistic models (DDPM). arXiv
-
Nichol & Dhariwal (2021). Improved denoising diffusion probabilistic models. arXiv
-
Ronneberger et al. (2015). U-Net: Convolutional networks for biomedical image segmentation. arXiv
-
Vaswani et al. (2017). Attention is all you need. arXiv
-
He et al. (2015). Deep residual learning for image recognition (ResNet). arXiv
-
Dosovitskiy et al. (2020). An image is worth 16×16 words (Vision Transformer). arXiv
-
Peebles & Xie (2022). Scalable diffusion models with transformers (DiT). arXiv
-
Dhariwal & Nichol (2021). Diffusion models beat GANs on image synthesis (ADM). arXiv
-
Ho & Salimans (2022). Classifier-free diffusion guidance. arXiv
-
Song et al. (2020). Denoising diffusion implicit models (DDIM). arXiv